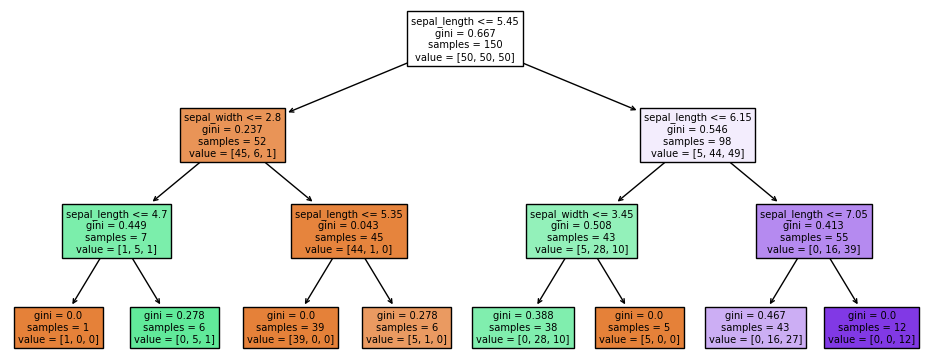
Repitamos el entrenamiento del modelo a partir del dataset Iris limitando la profundidad máxima del árbol:
model = DecisionTreeClassifier(max_depth = 3, random_state = 0)
model.fit(X.values, y)
model.fit(X.values, y)

Veamos las fronteras de decisión de este nuevo modelo:
show_boundaries(model, X.values, None, y, None, iris.species.unique())
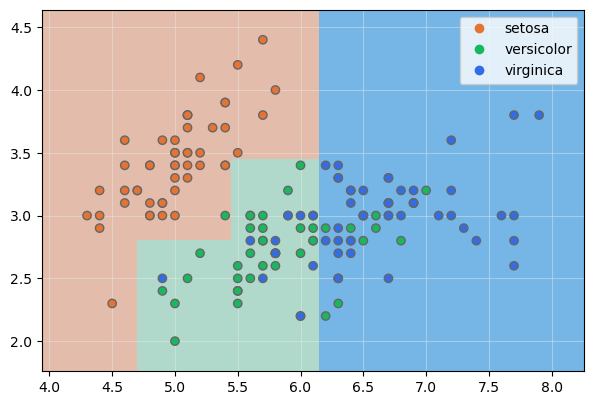
Es evidente que hemos reducido el sobreentrenamiento. Mostremos el árbol creado:
fig, ax = plt.subplots(figsize = (12, 5))
plot_tree(model, filled = True, feature_names = X.columns)
plt.show()
plot_tree(model, filled = True, feature_names = X.columns)
plt.show()