Analicemos el impacto del número de vecinos escogido en el "score" del modelo. Ahora vamos a considerar el dataset Iris completo:
iris = sns.load_dataset("Iris")
iris["label"] = iris.species.astype("category").cat.codes
iris["label"] = iris.species.astype("category").cat.codes
X = iris.drop(["species", "label"], axis = 1)
y = iris.label
y = iris.label
Dividimos el dataset:
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 0)
Ahora entrenemos 10 modelos, con k tomando valores en el rango [1, 11):
train_scores = []
test_scores = []
for k in range(1, 11):
model = KNeighborsClassifier(n_neighbors = k)
model.fit(X_train.values, y_train)
train_scores.append(model.score(X_train.values, y_train))
test_scores.append(model.score(X_test.values, y_test))
test_scores = []
for k in range(1, 11):
model = KNeighborsClassifier(n_neighbors = k)
model.fit(X_train.values, y_train)
train_scores.append(model.score(X_train.values, y_train))
test_scores.append(model.score(X_test.values, y_test))
Visualicemos el resultado:
fig, ax = plt.subplots(figsize = (8, 4.8))
ax.plot(range(1, 11), train_scores, label = "Train dataset")
ax.plot(range(1, 11), test_scores, label = "Test dataset")
ax.set_xticks(range(1, 11), labels = range(1, 11))
ax.grid(color = "#EEEEEE", zorder = 0)
ax.set_ylim(0, 1)
ax.legend()
plt.show()
ax.plot(range(1, 11), train_scores, label = "Train dataset")
ax.plot(range(1, 11), test_scores, label = "Test dataset")
ax.set_xticks(range(1, 11), labels = range(1, 11))
ax.grid(color = "#EEEEEE", zorder = 0)
ax.set_ylim(0, 1)
ax.legend()
plt.show()
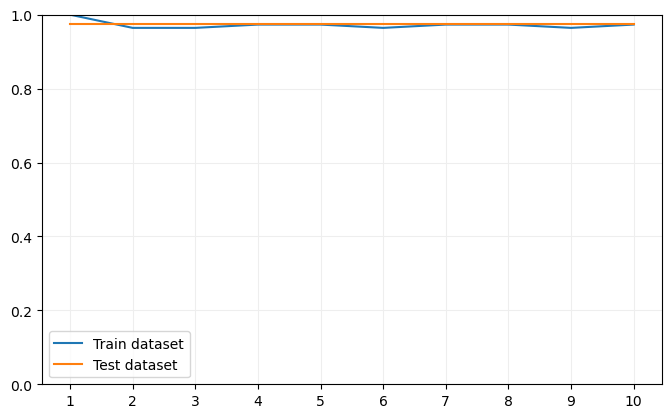
Obtenemos valores muy elevados tanto para el dataset de entrenamiento como para el de validación, debido a que el número de muestras no es muy elevado y a que las clases de este dataset están fuertemente relacionadas desde un punto de vista espacial.