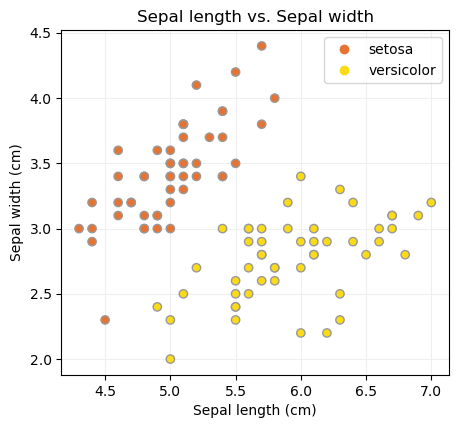
Comencemos visualizando los datos con los que estamos trabajando ahora:
ax.set_aspect("equal")
scatter = ax.scatter(
x = X.iloc[:, 0], y = X.iloc[:, 1],
c = iris.label, zorder = 2, edgecolor = "#999999",
cmap = ListedColormap(["#E67332", "#FADB15"])
)
ax.set_title("Sepal length vs. Sepal width")
ax.set_xlabel("Sepal length (cm)")
ax.set_ylabel("Sepal width (cm)")
ax.legend(
handles = scatter.legend_elements()[0],
labels = list(iris.species.unique())
)
ax.grid(color = "#EEEEEE", zorder = 1, alpha = 0.9)
plt.show()
Para realizar una predicción, en Scikit-learn no tenemos más que usar (normalmente) el método .predict() asociado a la instancia del algoritmo correspondiente. A este método deberemos pasar una estructura con la muestra o las muestras para las que queremos obtener la predicción. El único matiz aquí es que, si el conjunto de entrenamiento X era una estructura bidimensional, también la estructura que pasemos al método .predict() deberá serlo y, obviamente, deberá respetarse el orden en el que pasemos las características predictivas.
Por ejemplo, viendo el gráfico de dispersión anterior vemos que para una muestra con una longitud de sépalo de 5.5 cm y un ancho de sépalo de 4.0 cm la case a asignar debería ser setosa (la clase 0). Veamos qué predice nuestro modelo:
La predicción es que la muestra en cuestión pertenece a la clase 0.