Scikit-Learn ofrece varias clases para la implementación de algoritmos de tipo Support Vector Machines, y la forma en la que encaran los escenarios multiclase no es la misma. Así, la clase SVC que hemos usado hasta ahora, y la clase NuSVC implementan el enfoque "One-vs-One", mientras que la clase LinearSVC implementa el enfoque "One-vs-Rest". En todo caso, todas las clases soportan escenarios multiclase, de forma que hagamos un ejemplo con el dataset Iris considerando las tres clases de flores:
iris["label"] = iris.species.astype("category").cat.codes
X = iris[["sepal_length", "sepal_width"]].values
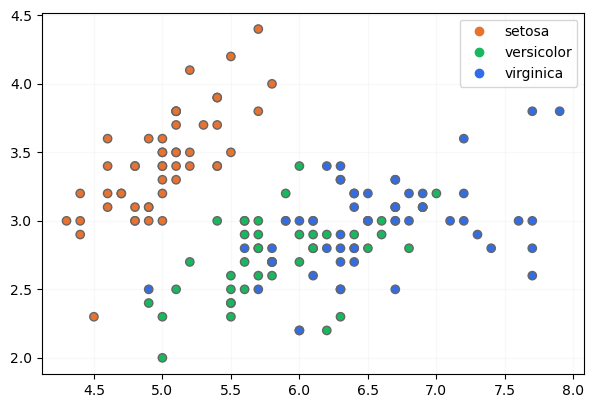
Recordemos la disposición de estos datos:
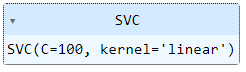
Entrenemos un modelo con alta regularización:
model.fit(X, y)
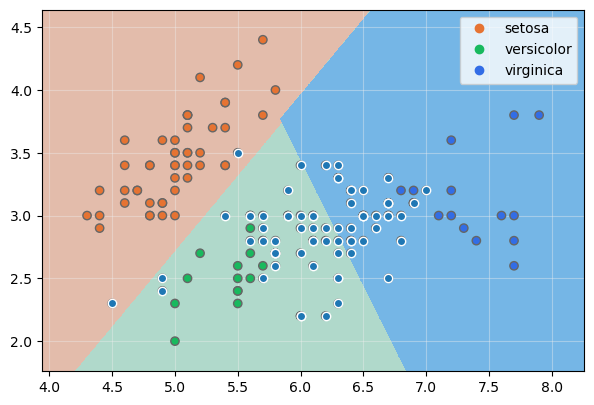
Mostremos las fronteras de decisión:
El número de muestras mal clasificadas quedan reducidas a las especies versicolor y virginica, aunque debemos recordar que al usar un parámetro de regularización alto, los márgenes son menores y la capacidad de generalización del resultado puede verse afectada.
El número de vectores de soporte para cada clase es:
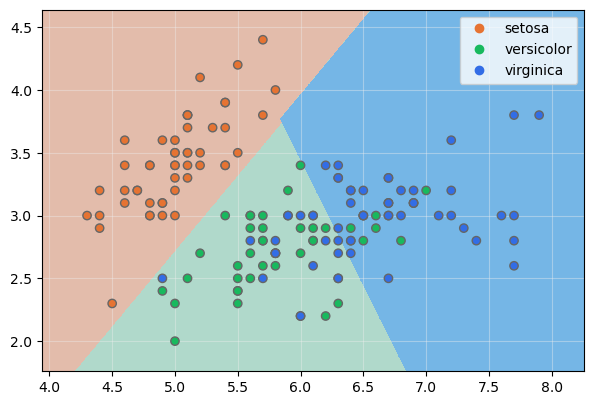
Resulta sencillo mostrar sobre la gráfica anterior estos vectores de soporte añadiéndoles un borde blanco:
ax.scatter(x = X[model.support_, 0], y = X[model.support_, 1], edgecolor = "white", zorder = 99)
plt.show()