Revisemos los parámetros principales de las clase MLPClassifier:
hidden_layer_sizes
Ya hemos visto aparecer este parámetro en el ejemplo anterior: se trata de una tupla conteniendo el número de neuronas en cada capa oculta: (5,) haría referencia a una capa oculta de 5 neuronas y (50, 20, 10) haría referencia a tres capas ocultas de 50, 20 y 10 neuronas artificiales respectivamente.
activation
Función de activación para las neuronas artificiales de las capas ocultas (en Scikit-Learn no es posible establecer funciones de activación distintas para cada capa). Hay cuatro opciones disponibles:
- identity, función identidad que devuelve el mismo valor que recibe: f(x) = x
- logistic, función logística: f(x) = 1 / (1 + exp(-x))
- tanh, función tangente hiperbólica: f(x) = tanh(x)
- relu, (opción por defecto) función "rectified linear unit": f(x) = max(0, x)
Obsérvese que, a pesar del nombre de las clases (Multilayer Perceptron), no se incluye como opción la función escalón (usada en el perceptrón de Frank Rosenblatt) -es decir, no es posible simular un perceptrón con esta clase-.
solver
El parámetro solver determina el optimizador a utilizar para el cálculo del mínimo de la función de coste. Tres opciones disponibles:
- lbfgs, optimizador de la familia de los métodos casi-Newton
- sgd, descenso de gradiente estocástico
- adam (opción por defecto)
max_iter
El parámetro max_iter determina el número máximo de epochs durante las que se va a entrenar el modelo. El valor por defecto es 200. Si el modelo converge antes de este número de iteraciones, se detiene el aprendizaje.
learning_rate
Tasa de aprendizaje usada durante la actualización de los pesos. Se ofrecen tres opciones:
- constant, valor constante especificado por el parámetro learning_rate_init, aplicable solo cuando el solver es "sgd" o "adam".
- invscaling, tasa de aprendizaje gradualmente decreciente usando, en cada paso t, la siguiente función:
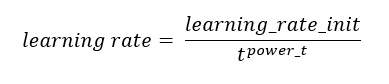
Este método solo es aplicable cuando el solver es "sgd". El valor de power_t en la anterior función viene dado por el parámetro homólogo, power_t, que, por defecto, toma el valor 0.5
- adaptative. Este método mantiene la tasa de aprendizaje constante e igual a learning_rate_init mientras se confirme una reducción en el valor de la función de coste durante el entrenamiento. Si durante 2 epochs consecutivas no se produce una reducción de, al menos, un valor mínimo dado por el parámetro tol, o -si se está utilizando parada temprana- no se produce un aumento del score (métrica de bondad del modelo) que corresponda en el conjunto de validación, la tasa de aprendizaje se divide por 5.
shuffle
Este parámetro determina si las muestras se desordenan antes de cada epoch o no. Solo se considera si el solver es "sgd" o "adam".
alpha
El parámetro alpha determina la penalización L2 a aplicar sobre los pesos que ponderan los valores de entrada de las neuronas. Un valor de alpha más elevado supondrá pesos menores y una menor varianza (frecuente en entornos de sobreentrenamiento).
tol y n_iter_no_change
Cuando la función de coste no mejore por lo menos tol durante n_iter_no_change epochs (valor dado por el parámetro homónimo), -salvo que se esté entrenando la red con una tasa de aprendizaje adaptativa- se considerará que la red neuronal ha sido entrenada y se parará el proceso de entrenamiento.
momentum y nesterovs_momentum
Trabajando con el optimizador "sgd" (Stochastic Gradient Descent) es posible configurarlo de forma que se aplique momentum de Nesterov (de forma que las actualizaciones del algoritmo Gradient Descent se calculen como combinación lineal del nuevo vector y la última actualización).
early_stopping y validation_fraction
Si el parámetro early_stopping se fija con el valor True, se reservará el 10% de los datos de entrenamiento como conjunto de validación y se dará fin al entrenamiento en cuanto la mejora del modelo en dicho conjunto no sea, al menos, de tol en n_iter_no_change epochs consecutivas. Solo se considerará si el solver es "sgd" o "adam". El porcentaje de datos a reservar como conjunto de validación puede configurarse con el parámetro validation_fraction.