De forma semejante a como hemos hecho con los algoritmos previamente revisados, probemos el Perceptrón Multicapa con el dataset Iris. Comenzamos cargando los datos y codificando la etiqueta:
iris["label"] = iris.species.astype("category").cat.codes
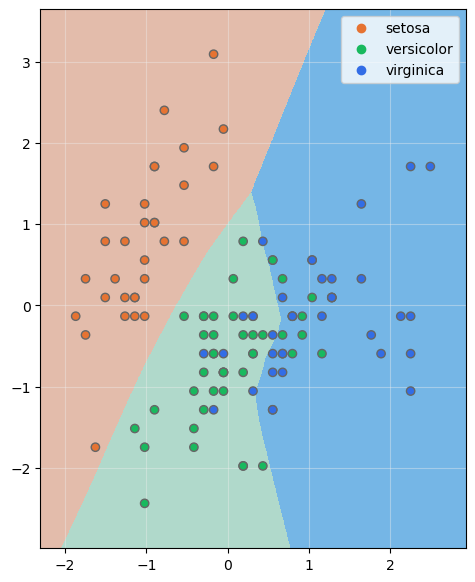
Como queremos mostrar la frontera de decisión, nos quedamos solo con dos características predictivas:
y = iris.label
A continuación vamos a escalar los datos, lo que favorece la convergencia del algoritmo al requerir menos iteraciones y modificaciones menores en los parámetros. Para ello vamos a aplicar el escalador StandardScaler de Scikit-Learn:
X = scaler.fit_transform(X)
Ahora creamos los datasets de entrenamiento y validación:
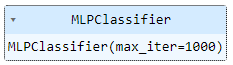
Por último, importamos la clase, la instanciamos y entrenamos el algoritmo:
Vamos a entrenar una red neuronal con la estructura por defecto (una única capa oculta con 100 neuronas). Para asegurar que el algoritmo converge, vamos a establecer un número máximo de 1000 epochs (el valor por defecto es 200):
model.fit(X_train, y_train)
Comprobemos el porcentaje de aciertos en el dataset de validación:
Y visualicemos las fronteras de decisión (recordemos que hemos escalado las dos características predictivas):