En Scikit-Learn, la clase MLPClassifier recibe como primer argumento el parámetro hidden_layer_sizes, que controla la estructura de la red neuronal. Este argumento debe ser una tupla cuyos valores representen el número de neuronas artificiales en cada capa oculta. Así, (2,) representaría una única capa oculta con 2 neuronas, o (5, 3) representaría dos capas ocultas con 5 y 3 neuronas artificiales respectivamente.
En escenarios de clasificación, la implementación de Scikit-Learn crea en la capa de salida tantas neuronas como clases existan, excepto si se trata de clasificación binaria, en cuyo caso solo se incluye una neurona cuya función de activación determina la clase a devolver como predicción.
Es decir, la estructura de la red neuronal que vamos a crear es la siguiente:
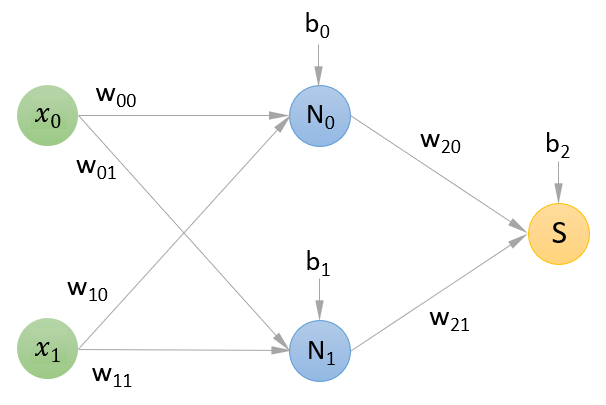
donde:
- x0 y x1 son las características predictivas que se van a pasar por la red
- N0 y N1 son las dos neuronas que componen la capa oculta
- S es la neurona que compone la capa de salida (una sola, pues estamos trabajando en un entorno de clasificación binaria)
- w00 es el peso por el que se va a multiplicar x0 en la entrada a la neurona N0
- w01 es el peso por el que se va a multiplicar x0 en la entrada a la neurona N1
- w10 es el peso por el que se va a multiplicar x1 en la entrada a la neurona N0
- w11 es el peso por el que se va a multiplicar x1 en la entrada a la neurona N1
- b0 es el bias a sumar a los valores de entrada ponderados de la neurona N0
- b1 es el bias a sumar a los valores de entrada ponderados de la neurona N1
- w20 es el peso por el que se va a multiplicar la salida de la neurona N0 en la entrada a la neurona de salida S
- w21 es el peso por el que se va a multiplicar la salida de la neurona N1 en la entrada a la neurona de salida S
- b2 es el bias a sumar a los valores de entrada ponderados de la neurona de salida S
En resumen, trabajaremos con 6 pesos (llamados coeficientes en Scikit-Learn) y tres bias a añadir a los valores de entrada ponderados de las neuronas (llamados interceptores en Scikit-Learn).