The GENERATE function returns a table formed by the Cartesian product of all the rows of the first table and the rows of the second table after being evaluated in the row context of each of the rows of the first one. Or, in other words, for each of the rows in the first table, a row context is created that is applied to the second table before the join is performed.
GENERATE(
table1,
table2
)
- table1: First table, whose rows will generate the row context.
- table2: Second table, whose rows are going to be contextualized before applying the Cartesian product.
The GENERATE function returns a table that is the result of performing the Cartesian product between the rows of the first table and the rows of the second table after being contextualized.
Tables must have columns with mismatched names, otherwise the GENERATE function will return an error.
In this first example we start from the following two tables:
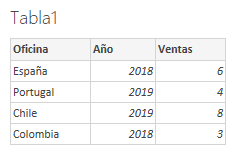
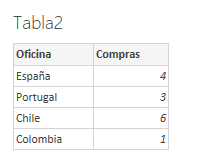
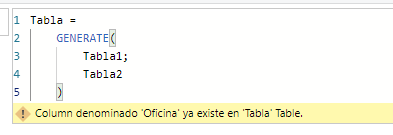
Note that these tables have a common field ("Oficina"), so creating a calculated table using the GENERATE function will return an error:
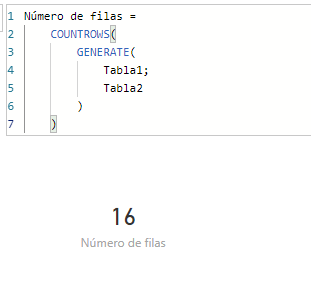
Interestingly, it is possible to use this function to generate an intermediate table on which to apply other functions:
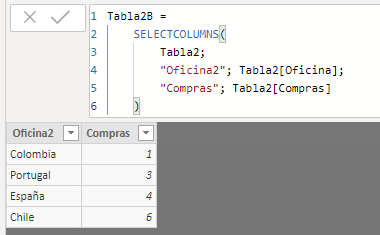
Since, in this exercise, we want to visualize the table resulting from applying the GENERATE function to our two data tables, we are going to generate a new table, Tabla2B , with the same fields as Tabla2 but changing the name of the "Oficina" field, something which we will do using the SELECTCOLUMNS function:
Tabla2B =
SELECTCOLUMNS(
Tabla2;
"Oficina2", Tabla2[Oficina];
"Compras", Tabla2[Compras]
)
Now we could apply the GENERATE function to the tables Tabla1 and Tabla2B. If we do it, the result is the same as we would have when using the CROSSJOIN function:
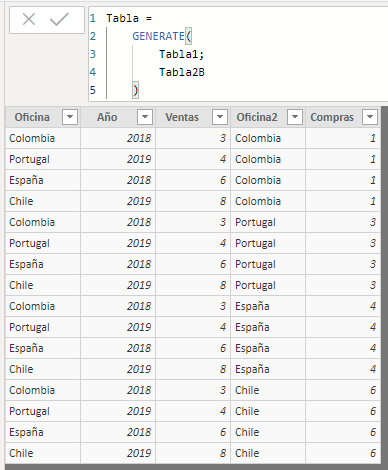
In this case, applying the row context generated by each of the rows in the first table has not modified the result of the Cartesian product.
But, if instead of applying the GENERATE function to Tabla2B, we do it to the result of filtering said table considering the fields of Tabla1, the result is quite different. Let's do this filtering with the FILTER function:
Tabla =
GENERATE(
Tabla1,
FILTER(
Tabla2B,
Tabla1[Oficina] = Tabla2B[Oficina2]
)
)
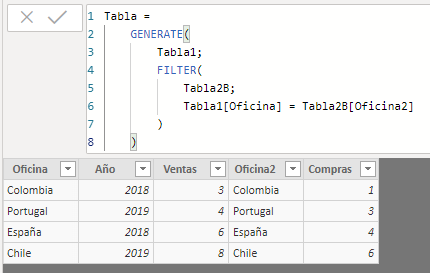
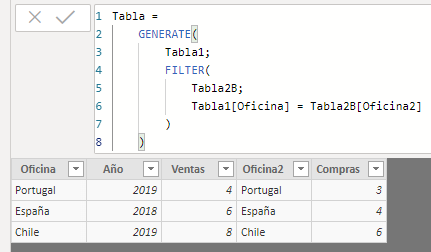
Let's see what happened:
The function has traversed each of the rows in the first table, creating a row context for each of them. Thus, for the first one, the row context is given by, among other things, "Oficina " = "España". Next, this row context has been applied to the second table, which is the result of applying a filter to Tabla2B according to which the value of the Oficina2 field must match the result of the Oficina field of the first table. As a result of applying this row context, the second table has been reduced to those rows in which the Oficina2 field takes the value "España" (a single record in this case). Next, the row being considered from the first table has been multiplied by each and every one of the rows from the second table after applying the context (a single row). The result of this first step is -in this example- a single row with the fields of both tables for the records in which the name of the office is "España".
After evaluating the first row of the first table, the same procedure would be carried out with each and every one of the other rows of this table, generating a row context, applying it to the second table, and multiplying the row of the first table by the resulting ones in the second table.
In this example, where all the field values for the offices are present in both tables, the result is similar to an inner join.
To test this last statement, let's repeat the operation including an office in the first table that does not exist in the second, and one in the second that does not exist in the first:
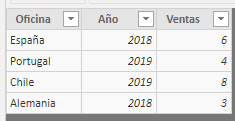
Let's now apply the GENERATE function with the filter seen:
Indeed, when for a row in the first table there is not at least one other equivalent in the second, the product is an empty set (and no result is returned). And the same happens when a row from the second table never gets to be multiplied by any of the first table because it does not have an equivalent.
Of course, we are not obliged to work with a single condition. Suppose we start from the following tables:
After changing the name of the "Oficina" field in the second table, we could apply the GENERATE function as follows:
Tabla =
GENERATE(
Tabla1;
FILTER(
Tabla2B;
Tabla1[Oficina] = Tabla2B[Oficina2] &&
Tabla1[Año] <= 2018
)
)
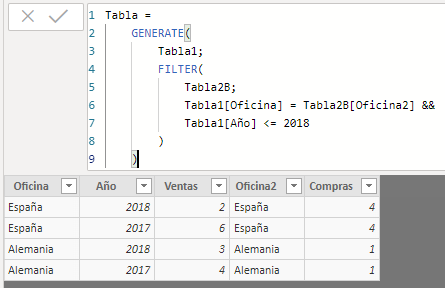
In this case we are creating a row context that includes the name of the office of the row being considered in the first table and that the year for said row is less than or equal to 2018. If the result of applying this row context to the second table is an empty table, no row will be generated in the table resulting from applying the GENERATE function.