The GROUPBY function is similar to the SUMMARIZE function but only supports iterative functions (SUMX, MINX, etc.) since an implicit CALCULATE is not executed on expressions. The groups formed are not affected by the filter context.
GROUPBY(
table,
groupBy_columnName
[, groupBy_columnName]…
[, name,
expression]…
)
- table: Reference to a table, or DAX expression that returns a table.
- groupBy_columnName: Fully qualified name of an existing column in the previous table or in a related table to create the groups based on the values found in it. It cannot be an expression.
- name: Name given to the total calculated in expression.
- expression: DAX expression that returns a scalar that will be used to calculate the totals. This expression must be of type iterative and will include the CURRENTGROUP function as the first argument.
The GROUPBY function returns a table having as columns those specified in the groupBy_columnName argument (values that will specify the aggregation criteria) and those added as name that will contain the result of evaluating expression for the combinations of the groupBy_columnName fields.
Each column that we add as a name must be accompanied by the expression that defines it. In any other case the function will return an error.
The groupBy_columnName fields must belong either to the table indicated in the first argument, or to a related table.
Names added as name must be enclosed in double quotes.
The number of rows in the table will be determined by the number of different values that the groupBy_columnName fields take. If only one field is included that takes 4 different values, the result will be a table with 4 rows. If two values are included that take, respectively, 3 and 4 different values, the result will be a table with 4 x 3 = 12 rows (one for each combination of the values of both fields).
The GROUPBY function is executed as follows:
- It begins with the specified table and the related tables involved.
- Creates groups based on the values contained in the groupBy_columnName arguments.
- For each group, it evaluates the indicated expressions, but, contrary to what happens with the SUMMARIZE function, an implicit CALCULATE is not executed, therefore, the filter context is not considered.
The GROUPBY function can be slower than the SUMMARIZE or SUMMARIZECOLUMNS functions. However, the fact of calculating the expressions in a row context allows addressing certain scenarios that the aforementioned functions do not allow.
Within the iterative function, the CURRENTGROUP function must be used as the first argument.
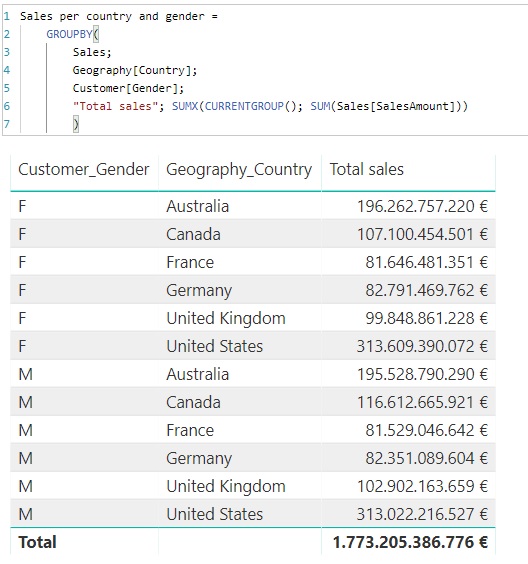
We start in this example from a sales table (Sales), and fields in related remote tables that contain the name of the country in which the sale occurs (Geography[Country]) , and the buyer's gender (Customer[Gender]). The goal is to create a table that shows the sales by country and gender of the buyer. The code would be the following:
Sales per country and gender =
GROUPBY(
Sales,
Geography[Country],
Customer[Gender],
"Total sales", SUMX(CURRENTGROUP(), SUM(Sales[SalesAmount]))
)
It can be seen the use of the CURRENTGROUP function as the first argument of the SUMX iterative function.
If we take the resulting fields to a table, the result is the following:
Continuing with the same example, we can add a data segmentation with the list of countries and select one of them:
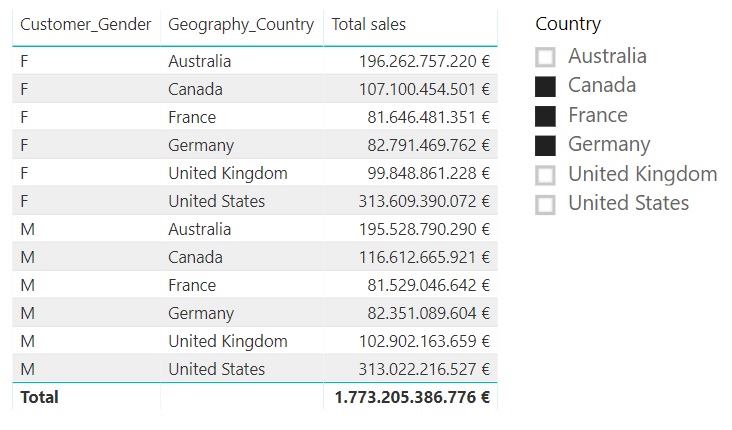
We see how, as could be expected, the table is not affected by the filter context.